📌 Gradient Descent(경사 하강법) 종류 완벽 정리
Batch GD, SGD, Mini-Batch GD 차이점 비교 & 선택 가이드
머신러닝과 딥러닝 모델을 학습할 때, 가장 중요한 최적화 알고리즘 중 하나가 **Gradient Descent(경사 하강법)**이다. 하지만 경사 하강법은 데이터 처리 방식에 따라 크게 Batch Gradient Descent, Stochastic Gradient Descent(SGD), Mini-Batch Gradient Descent 3가지로 나뉜다.
그렇다면, 이 3가지 방식은 어떻게 다를까? 그리고 어떤 상황에서 어떤 방법을 써야 할까?
이번 포스팅에서는 Gradient Descent의 핵심 개념과 종류별 차이점, 활용법을 그림과 도표로 직관적으로 정리해보겠다. 🚀
🧩 Gradient Descent란?
Gradient Descent(경사 하강법)은 손실 함수(Loss Function)의 최소값을 찾기 위해 가중치(Weight)를 조정하는 최적화 알고리즘이다. 즉, 모델이 더 나은 예측을 할 수 있도록 오차(Loss)를 줄이는 방향으로 가중치를 조정하는 과정이다.
🎯 경사 하강법의 핵심 개념
✅ 현재 위치에서 기울기(Gradient)를 계산하여 손실을 줄이는 방향으로 이동
✅ 학습률(Learning Rate)에 따라 이동 속도 조절
✅ 최적값(Global Minimum)을 찾는 것이 목표
🔥 Batch GD vs SGD vs Mini-Batch GD 차이점 비교
📌 Batch Gradient Descent (GD)
🟢 특징
- 전체 데이터셋을 한 번에 사용하여 기울기를 계산하고 가중치를 업데이트함.
- 학습 과정이 부드럽고 안정적이나, 데이터가 크면 계산이 매우 느려질 수 있음.
🟢 장점
✅ 안정적인 수렴 과정
✅ 부드러운 최적화 경로
🔴 단점
❌ 데이터셋이 클 경우 연산 속도가 느림
❌ 메모리 사용량이 많음
📌 사용 사례: 데이터 크기가 작고, 안정적인 학습이 필요한 경우

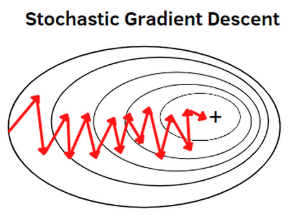
📌 Stochastic Gradient Descent (SGD)
🟢 특징
- 한 번의 업데이트에 단 하나의 샘플만 사용하여 가중치를 조정.
- 빠른 업데이트가 가능하지만, 최적화 경로가 불안정하여 진동할 수 있음.
🟢 장점
✅ 매우 빠른 학습 가능
✅ 지역 최소점(Local Minimum)을 탈출할 가능성이 높음
🔴 단점
❌ 최적화 경로가 불안정하여 최적점 근처에서 진동 가능
❌ 특정 패턴을 따르는 데이터에 과적합될 가능성이 있음
📌 사용 사례: 실시간 학습, 데이터셋이 매우 크고 빠른 최적화가 필요할 때
📌 Mini-Batch Gradient Descent
🟢 특징
- Batch GD와 SGD의 중간 형태로, 소규모 데이터 묶음(Mini-Batch)을 사용하여 업데이트 진행.
- 일반적으로 **Batch 크기(b)**는 16, 32, 64, 128 등의 값으로 설정됨.
🟢 장점
✅ 계산 효율이 뛰어나며, GPU 가속과 잘 맞음
✅ Batch GD보다 빠르고, SGD보다 안정적
✅ 최적화 경로가 부드러워 일반적으로 가장 좋은 성능을 보임
🔴 단점
❌ Batch 크기 선택에 따라 성능이 달라질 수 있음
❌ 너무 작은 Batch 크기를 선택하면 SGD처럼 불안정해질 수 있음
📌 사용 사례: 딥러닝에서 가장 일반적으로 사용 (CNN, Transformer, LSTM 등)

📊 비교 요약 도표
| 방식 | 데이터 사용 방식 | 장점 | 단점 | 사용 사례 |
| Batch GD | 전체 데이터셋 사용 | ✅ 안정적인 최적화, 부드러운 학습 경로 | ❌ 데이터가 크면 느리고 메모리 사용량 많음 | 데이터 크기가 작을 때 |
| SGD | 랜덤으로 하나의 샘플 사용 | ✅ 빠른 업데이트, 실시간 학습 가능 | ❌ 최적화 경로가 불안정, 진동 발생 가능 | 실시간 학습, 데이터가 클 때 |
| Mini-Batch GD | 일부 데이터(Batch) 사용 | ✅ 균형 잡힌 성능, 속도와 안정성 모두 좋음 | ❌ Batch 크기에 따라 성능이 달라질 수 있음 | 딥러닝에서 가장 일반적으로 사용 |
🚀 결론: 어떤 방법을 선택해야 할까?
✅ 데이터가 작고 계산 부담이 적다면? → Batch Gradient Descent
✅ 실시간 학습이 필요하거나 데이터가 매우 크다면? → SGD
✅ 대부분의 딥러닝 모델에서는? → Mini-Batch Gradient Descent (추천!)
실무에서는 Mini-Batch Gradient Descent가 가장 널리 사용되며,
Batch 크기를 32, 64, 128과 같은 2의 배수로 설정하는 것이 일반적이다. 🚀
'02. 딥러닝' 카테고리의 다른 글
| 00006. 🎢 딥러닝의 핵심: 경사 하강법과 역전파! (0) | 2025.03.19 |
|---|---|
| 00005. 🎢 기울기 벡터는 어디로 가라고 하는 걸까? - 딥러닝의 비밀! (1) | 2025.03.19 |
| 00004. 최적화 알고리즘 비교: Momentum, AdaGrad, RMSprop, Adam (0) | 2025.03.11 |
| 00003. Learning Rate란? 머신러닝과 딥러닝에서의 역할 (0) | 2025.03.11 |
| 00002. 🚀 Sigmoid 함수를 쓰면 왜 기울기 소실(Gradient Vanishing)이 발생할까? (0) | 2025.03.10 |

